More than idle radio chatter


Ominous What are the odds? Drew a nelson queuing at the Proms for Catherine Lamb's the other week.
Sync with a pot of coffee, I put the radio on most days to help stay positive while working. Working from home, it makes me feel connected to the rest of the world. I love classical and Radio 3 is one of my favorite stations. So the moment came July that the BBC permanently switched to supporting HLS / DASH only. Shoutcast endpoints are gone save for World Service. No surprise really, there had been occasional on-air warnings about it.
Alright, let me take a second to update my Mac's Music.app playlist I thought. Except no, pasting in the new .m3u8 address over File > Open Stream URL like normal kept error-ing, which gave me a slight scare because I value my early evening Sean Rafferty and Katie Derham little fix and was I then to start using their Sounds branded app or ffplay(1) or what else for it? 🫤
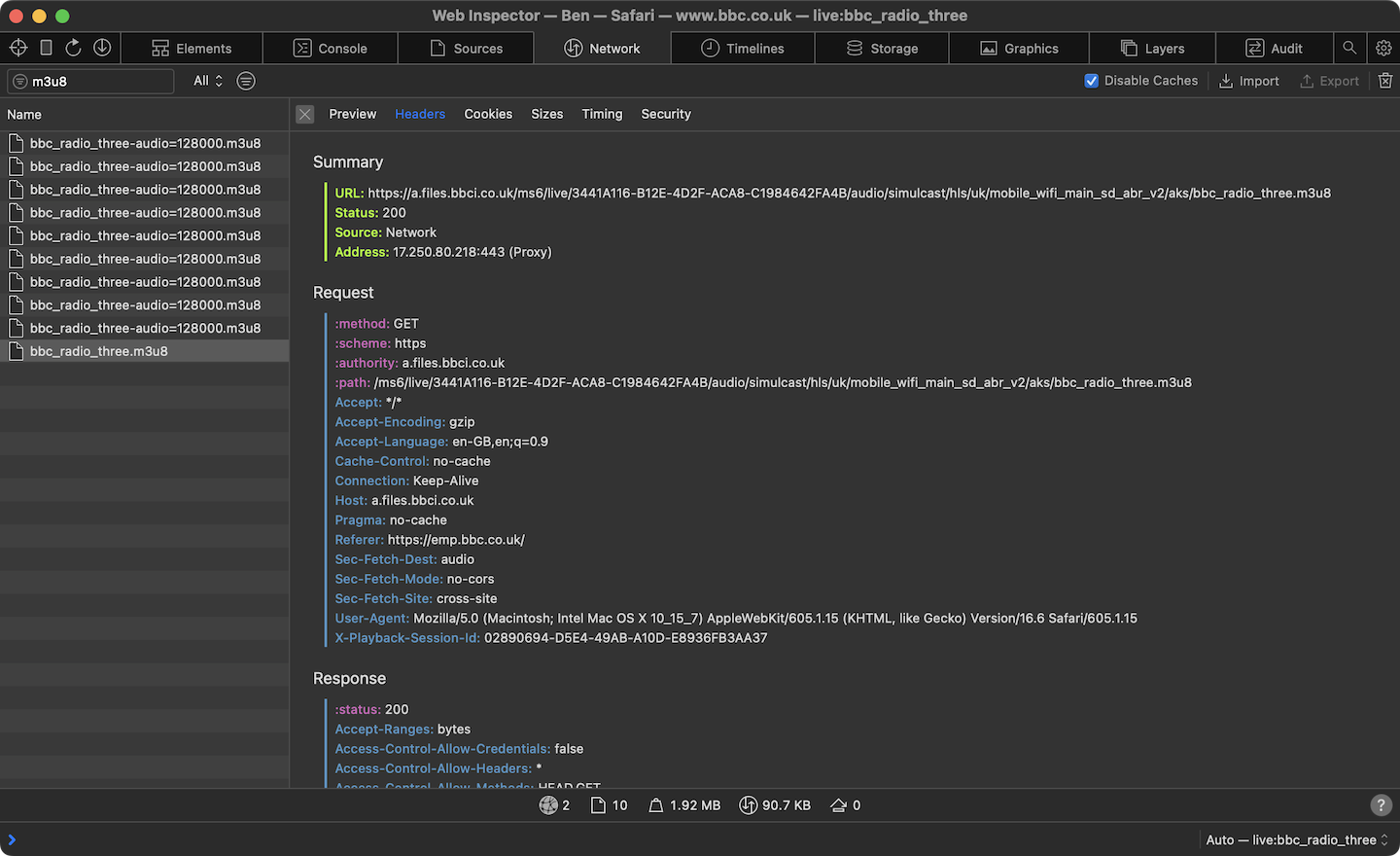
Fishing for Radio 3's new macOS compatible stream URL on mobile Safari. It's dash.js based playback otherwise.
Who would have guessed, simply replacing https: with itals: for a protocol does the trick as it happens. Given HLS is one of Apple's essentially, it might have been nice if that were better documented somehow, but okay writing a dedicated Swift Playgrounds mini app is just as easy in any case:
// HLS ready sample radio app.
import SwiftUI
import AVKit
@main
// NOTE: Make sure the stream is TLS served
// and the app network connection capable.
struct Radio: App {
var body: some Scene {
WindowGroup {
ContentView()
}
}
}
struct ContentView: View {
var player = AVPlayer(url: URL(string: "norewind.m3u8")!)
var body: some View {
VideoPlayer(player: player)
}
}

Mornings however, until recently anyway, WFMU's Wake 'n Bake with Clay Pigeon has been top banana for the understated professionalism, the wacky odd segments, fine melodies, and emphatic humanity. His old The Dusty Show first won me over with the vox pops. I had also never heard City Slang (1978) full-length bang boom blast through the airwaves before.
Purely my imagination, but listening to The Pidge I could almost trace distant links to back when I joined Dave from Negative FX on the record collector's trail in one of his London trips years ago. We were both drummers and that was a true gift of an experience for my music upbringing.
And with WFMU in general next to the massive legacy and singular freeform culture status, the archives are cosmic heritage grade treasure. It bothered my focus being unable to tune in regular hours half the summer, but at least I had the option of catching replays at night. Which is probably how, having since been forced to grow out of it, I wound up trying to say thanks and to account for things often lost in translation with a Paul Lansky's Idle Chatter (1985) inspired here mix.
Could I get enough of that track as student! The sound is crisp and tingly? It was written in Cmix for the IBM 3081 using Linear Predictive Coding (LPC), granular synthesis, and samples of his wife's Hannah MacKay's voice. Playing by ear, I may be missing certain angles, but am bringing in visual and time dynamic elements in return.

Back end
First up, sourcing the material. I can query the show's MP3 archive feed for the latest episode and XML parsing is trivial to achieve client-side using DOMParser.parseFromString(), but there are CORS restrictions to consider. And even if I were to proxy bypass those, which would be awfully bad form, at three hours those episodes are too long. Which means I need somewhere to: (a) edit the audio down, (b) serve it up for non opaque response fetching.
Let Internet Archive handle the last part. It was created for hosting media after all. Reason to donate. But where to have the files prepared and posted from? The OpenBSD my personal server runs on offers no XML utilities by default and I follow unapologetically aesthete strictly stick to base install sanctity rules there.
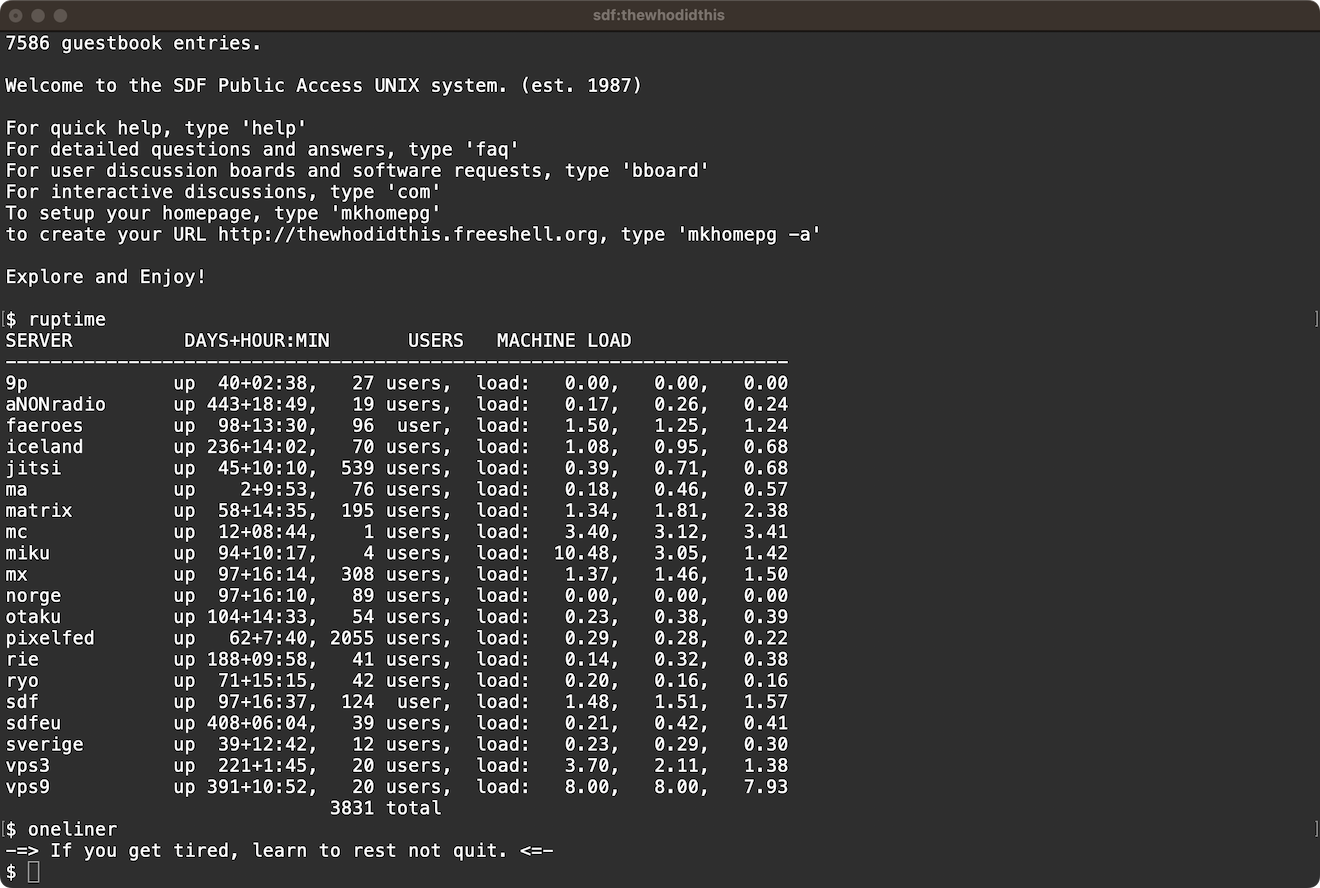
What cloud hosted VPS? The SDF Public Access UNIX System Est. 1987 is a wonder for running casual programs on a $36 minimum one-time lifetime membership plan.
The irony is whether I called e.g., grep "m3u" feed.xml | head -1 | cut -c 7-67 to tease out the playlist URL, when an xmllint(1) would perfectly fit the job, ia CLI binaries are the pex kind and still require Python 3 installed alongside. And properly substituting for a purpose-built tool as such without reinventing the wheel is more involved in practice than making ftp(1) authenticated API requests. And what about hacking the MP3?
No problem, fortunately the good people of the 1980s and '90s set up the NetBSD Super Dimension Fortress (SDF) that provides shell accounts pre-packed with the necessary UNIX goodies. SDF also seems uniquely appropriately epic a resource to match FMU's historic magnitude. I sent them a small present to qualify for arpa group permissions and was ready to go in a day, lovely. 🥰
# Get RSS feed, follow redirects, no progress / yes error logging. curl -LSs "https://www.wfmu.org/archivefeed/mp3/WA.xml" | # Drill down for the most recent episode's playlist link. xmllint --xpath "string(/rss/channel/item[1]/link)" - | # Ask for the actual .mp3 URL. xargs curl -LSs | # Download latest chatter, same settings. xargs curl -LSs > episode.mp3
I knew it as a lightweight MPlayer alternative, but mpg123(1) will decode and portion audio files as well:
# Take 1200 frames past the first 2400, roughly half a minute. mpg123 -s -q -k 2400 -n 1200 -w sample.wav episode.mp3
Convert back to .mp3 for the browser:
# Not overly worried about a hi-fi sound. lame -b 128 sample.wav sample.mp3
Install and configure the ia Python library:
# Double-check `~/.local/bin` is in `$PATH` to avoid warnings. python -m pip install internetarchive # Interactively commit API credentials into # `~/.config/internetarchive/ia.ini`. ia configure
Set metadata and upload:
ia upload justmoreidlechatternot sample.mp3 -q -r sample.mp3 \ # A test collection is also available. Items in it are # automatically removed after approximately 30 days. -m "collection:opensource_audio" \ # Give it a timestamp for a title. -m "title:$(date +%Y%m%d%s)" \ -m "mediatype:audio" \ -m "year:$(date +%Y)" \ # Add a custom flag for search filtering. -m "chatter:NOT"
That takes care of producing my sample. I keep the above commands in a Makefile, which I find more accessible than shell scripts. Wrapping up server-side, I want the ability to resupply from time to time. Conveniently, SDF reserve cron(8) for members higher up the subscription ladder. How do I repeat schedule when crontab(1) is off limits? By way of procmail(1) the autonomous mail processor of course! 😜
Given a .procmailrc of:
LOGFILE=$HOME/.procmail/log
PATH=$HOME/.local/bin:${PATH}
:0:
* ^From: from
* ^Subject: Chatter
|cd justmoreidlechatternot; make
I can then trigger my mechanism ad lib or e.g., @monthly with:
# Subject and sender are the cues. echo "" | mail -s "Chatter" -r from to
Front end
Smashing! And on to the browser part: To offset the retro pipeline magic, I should be looking at modern web platform features where possible and have been very excited lately about combining audio destination and canvas capture streams over <video>. There are a few quirks to be aware of, but it allows for picture-in-picture and fullscreen viewing and for frame rate throttling out of the box. I've had some luck with the following for a boilerplate so far:
// Worth holding with page markup JS enabled or not.
const video = document.querySelector("video")
// Turn off alpha for better performance.
const drawing = document.createElement("canvas")
.getContext("2d", { alpha: false })
// User action required.
video.addEventListener("click", function SingleShotClickHandler() {
const audio = new AudioContext()
const gain = 0.75
const destination = audio.createMediaStreamDestination()
const [track] = destination.stream.getAudioTracks()
video.srcObject.addTrack(track)
// Creating audio nodes using constructors has advantages
// over the older factory methods according to MDN.
const master = new GainNode(audio, { gain })
master.connect(destination)
// Legit using the same node for both
// time and frequency domain reads.
const analyser = new AnalyserNode(audio, { fftSize: 128 })
const frequencies = new Uint8Array(analyser.fftSize)
const amplitudes = new Uint8Array(analyser.fftSize)
master.connect(analyser)
const loop = (time) => {
// …
// Be eccentric, store frame ids in a data attribute.
this.dataset.frame = requestAnimationFrame(loop)
}
this.onpause = () => {
audio.suspend().then(() => {
this.dataset.frame =
cancelAnimationFrame(this.dataset.frame) ?? -1
})
}
this.onplay = () => {
audio.resume().then(() => {
this.dataset.frame = requestAnimationFrame(loop)
})
}
// Protect against starting multiple Chrome rAF loops.
if (!this.paused && !this.dataset.frame) {
this.dataset.frame = requestAnimationFrame(loop)
}
}, { once: true, passive: true })
// NOTE: Not to be confused with HTMLMediaElement.captureStream(),
// which takes no arguments. Set the frame rate to zero to
// disable automatic capture.
video.srcObject = drawing.canvas.captureStream(25)
video.onplay = function play() {
// Because Chrome be eating up control bar click events,
// but avoid on iOS Safari in particular.
if (this.audioTracks === undefined) {
this.click()
}
}
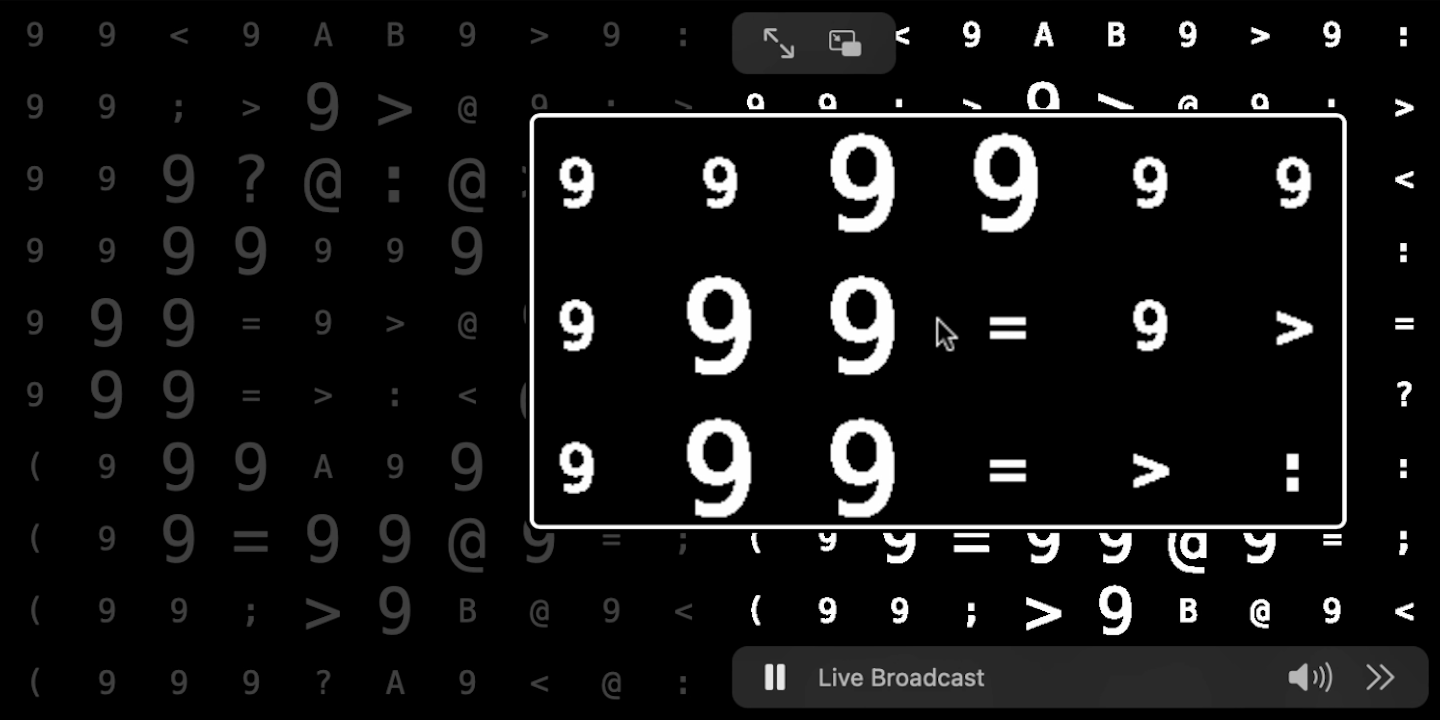
One gotcha of video streaming canvas animations: Attempting to clear the context ahead of each draw affects Safari text rendering quality, so fill it up with color instead.
Broadly speaking the idea is to split the sample into grains stacked across different voices and to monitor the mix in the time and frequency domains for driving the visuals. Nothing unconventional in terms of parameterization either: One basic PRNG seeded by the minute adds predictability within limits when resolving grain profiles. Panning alone is left completely to chance. Mental or not, number variables are derived from my hometown's area code 210.
// ☎️ Stop The Madness! const TEN = Number.parseInt(String(10).repeat(2), 2) // Have no fear. const N = (TEN / 2) - (TEN / TEN)
Sonically, I rely on OfflineAudioContext to render my grains in advance. I have four voices coming in on a short delay Canon style. I also have per grain low-pass filters in place to variably shield out high frequency information. Visually and dealing with mainly speech as input, laying out Unicode characters onto a grid goes great in my opinion.
// Mirror CSS settings.
const { backgroundColor, color, fontSize, fontFamily } = self.getComputedStyle(video)
drawing.textBaseline = "middle"
drawing.textAlign = "center"
drawing.font = `${fontSize} ${fontFamily}`
drawing.fillStyle = color
// Prefer built-in geometry types.
const { width, height } = video
const center = new DOMPoint(width / 2, height / 2)
const cell = new DOMRectReadOnly(0, 0, width / TEN, height / TEN)
const grid = new Array(TEN * TEN).fill("")
const lookup = [...chunk(grid.map((_, i) => i))]
function* chunk(a, n = 10) {
for (let i = 0; i < a.length; i += n) {
yield a.slice(i, i + n)
}
}
Parallel to updating each cell with frequency data, I'm rotating the grid in each cardinal direction every frame. Also, there had been talk of too much monkey business in my dimension as I took this up, so why not introduce a touch of HACKMEM-ish banana phenomenon topical bonus variation into the picture as well? 🙊
// For each animation frame at 25 fps:
const frame = Number(video.dataset.frame)
// These go from 0 to 255.
analyser.getByteFrequencyData(frequencies)
analyser.getByteTimeDomainData(amplitudes)
// Focus on the busiest bins.
frequencies
.slice(0, 32)
.forEach((v, i) => {
const word = String(v).padStart(3, " ").split("")
const step = frame % 64
word.forEach((n, j) => {
// Skip ASCII control characters.
grid[(i * 3) + j] = String.fromCharCode(Number(n) + step + 32)
})
})
let stop = -1
// Repeat until no empty cells (four times).
while ((stop = grid.indexOf("")) !== -1) {
// Take the last 3 items.
const body = grid.slice(0, stop).join("")
const last = body.slice(-3)
// Search for a random occurrence of that sequence in the grid.
const hits = []
for (let i = body.indexOf(last); i !== -1; i = body.indexOf(last, i + 1)) {
hits.push(i)
}
// Edit grid to include the next item.
const pick = Math.floor(Math.random() * hits.length)
const next = hits[pick]
grid.copyWithin(stop, next, next + 1)
}
// NOTE: This is selected cycling through a table of matrices
// calculated beforehand in the actual script.
lookup.forEach((a, row) => {
a.forEach((i, column) => {
const character = grid.at(i)
const point = new DOMPoint(column, row)
const { x, y } = new DOMMatrix()
// Spread.
.scale(cell.width, cell.height)
// Center.
.translate(1 / 2, 1 / 2)
// Start here.
.transformPoint(point)
drawing.fillText(character, Number.parseInt(x), Number.parseInt(y))
})
})
For color, I have ripples of competing compositing operations and hues tied to the signal's greatest peak blowing up center on out:
const amplitude = Math.max.apply(Math, amplitudes) / 128
for (let i = 0; i < N; i += 1) {
const j = i + 1
const radius = Number.parseInt((amplitude * frame / j) % (width / 2))
const hue = (amplitude * frame * j * 2) % 360
const saturation = 100 - j
const luminosity = i & 1 ? 50 : 5
drawing.save()
drawing.globalCompositeOperation = frame % 2 === 0 ? "overlay" : "color-dodge"
drawing.lineWidth = Math.round(radius / 2)
drawing.strokeStyle = `hsl(${hue}deg, ${saturation}%, ${luminosity}%)`
drawing.beginPath()
drawing.ellipse(center.x, center.y, radius, radius, 0, 0, Math.PI * 2)
drawing.stroke()
drawing.restore()
}
Tuketa-Tuk! Sweet life of a radio show percussive speech grains refreshing by mail at will, monthly, and every minute.
Granted it's a fairly common pattern, but is there anything wrong with observing a beginning, a middle, and an end for a scenario? Climax with a moment of silence halfway through:
const material = await fetch("sample.mp3")
.then(r => r.arrayBuffer())
.then(b => audio.decodeAudioData(b))
const halfway = audio.currentTime + material.duration
master.gain.setValueAtTime(gain, halfway + 1)
master.gain.setValueAtTime(0, halfway)
Then quit without reserve past twice the clip's duration:
if (currentTime > halfway * 2) {
audio.close().then(() => {
// Clean up thoroughly, page refresh mandatory.
const script = document.querySelector("script")
video.onplay = video.onpause = null
delete video.dataset.frame
video.srcObject.removeTrack(track)
video.removeAttribute("controls")
script?.remove()
})
}
Dead end (rejected)
I try to avoid inline styles and was tempted to use constructible stylesheets scaling my offscreen canvas for high resolution displays, but insertRule() is in fact no extra effort:
// Freshly landed in Safari 16.4 March '23.
const sheet = new CSSStyleSheet()
document.adoptedStyleSheets = [sheet]
// Calling before or after the assignment makes no difference.
sheet.replaceSync(`canvas { height: ${height}px; width: ${width}px; }`)
Reaching straight for fetch() to be loading the audio with may seem like an obvious choice, but leaves no room for indicating progress at the moment when XHR has a native event baked in already.
// Too soon! Recreating progress metering using the Fetch and Streams APIs.
const track = await fetch("sample.mp3")
.then(async (response) => {
if (response.ok) {
const total = Number(response.headers.get("content-length"))
const type = response.headers.get("content-type")
const chunks = []
// NOTE: Firefox has this already implemented. Other browsers
// can manage for await...of in separate situations though.
// github.com/whatwg/streams/issues/778
for await (const chunk of response.body) {
chunks.push(chunk)
const detail = chunks.reduce((a, b) => a + b.length, 0) / total
const p = new CustomEvent("fetch:progress", { detail })
self.dispatchEvent(p)
}
const result = new Uint8Array(...chunks)
return new Blob([result.buffer], { type })
}
})
.then(blob => new Audio(URL.createObjectURL(blob)))
No end, next steps
Because it's so characteristic of the original, I stopped short of giving the audio any LPC treatment. That would have been imitating too hard and banal, but it should be interesting to maybe include tone generators in future iterations. Finally and since so many parameters are always changing, adding MediaStream Recording API export functionality might be useful.